
因为腾讯云一直对博客多次提出整改,不胜其烦,主动注销了原来域名的备案,现在用这个二级域名作为博客地址。
更换域名
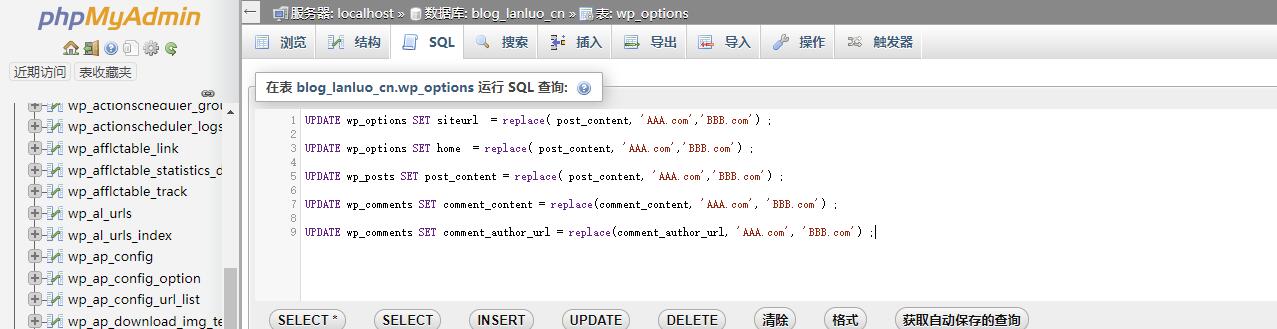
WordPress通常更换域名,只需要在数据库中进行如下操作即可
|
1 2 3 4 5 6 7 8 9 |
UPDATE wp_options SET siteurl = replace( siteurl, 'AAA.com','BBB.com') ; UPDATE wp_options SET home = replace( home, 'AAA.com','BBB.com') ; UPDATE wp_posts SET post_content = replace( post_content, 'AAA.com','BBB.com') ; UPDATE wp_comments SET comment_content = replace(comment_content, 'AAA.com', 'BBB.com') ; UPDATE wp_comments SET comment_author_url = replace(comment_author_url, 'AAA.com', 'BBB.com') ; |
将这其中的AAA.com(老域名)BBB.com(新域名)替换后,在MySQL中执行,如果有PHPmyadmin也是可以的。
这几行数据库命令的意思是:
- 更改网站域名AAA.com -> BBB.com;
- 更改网站首页域名AAA.com -> BBB.com;
- 更改网站文章内容域名AAA.com -> BBB.com;
- 更改网站评论内容域名AAA.com -> BBB.com;
- 更改网站作者主页域名AAA.com -> BBB.com;
以我的为例,我会替换为以下代码:
|
1 2 3 4 5 6 7 8 9 |
UPDATE wp_options SET siteurl = replace( siteurl, 'blog.lanluo.cn','blog.lanluo.cn') ; UPDATE wp_options SET home = replace( home, 'blog.lanluo.cn','blog.lanluo.cn') ; UPDATE wp_posts SET post_content = replace( post_content, 'blog.lanluo.cn','blog.lanluo.cn') ; UPDATE wp_comments SET comment_content = replace(comment_content, 'blog.lanluo.cn', 'blog.lanluo.cn') ; UPDATE wp_comments SET comment_author_url = replace(comment_author_url, 'blog.lanluo.cn', 'blog.lanluo.cn') ; |
平时更换域名,这样操作就行了,但是这次变更域名,并不是那么顺利,新上传的媒体链接任然是老域名的,所以,还需要进行如下操作:
替换媒体路径
|
1 |
UPDATE wp_options SET upload_url_path = replace( upload_url_path, 'AAA.com','BBB.com') ; |
替换upload_url_path上传路径URL为新域名即可。
原创文章,作者:蓝洛水深,如若转载,请注明出处:https://blog.lanluo.cn/9868
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 




