
网络爬虫和相关工具
网络爬虫的概念
网络爬虫(web crawler),以前经常称之为网络蜘蛛(spider),是按照一定的规则自动浏览万维网并获取信息的机器人程序(或脚本),曾经被广泛的应用于互联网搜索引擎。使用过互联网和浏览器的人都知道,网页中除了供用户阅读的文字信息之外,还包含一些超链接。网络爬虫系统正是通过网页中的超链接信息不断获得网络上的其它页面。正因如此,网络数据采集的过程就像一个爬虫或者蜘蛛在网络上漫游,所以才被形象的称为网络爬虫或者网络蜘蛛。
爬虫的应用领域
在理想的状态下,所有ICP(Internet Content Provider)都应该为自己的网站提供API接口来共享它们允许其他程序获取的数据,在这种情况下爬虫就不是必需品,国内比较有名的电商平台(如淘宝、京东等)、社交平台(如腾讯微博等)等网站都提供了自己的Open API,但是这类Open API通常会对可以抓取的数据以及抓取数据的频率进行限制。对于大多数的公司而言,及时的获取行业相关数据是企业生存的重要环节之一,然而大部分企业在行业数据方面的匮乏是其与生俱来的短板,合理的利用爬虫来获取数据并从中提取出有商业价值的信息是至关重要的。当然爬虫还有很多重要的应用领域,下面列举了其中的一部分:
-
- 搜索引擎
- 新闻聚合
- 社交应用
- 舆情监控
- 行业数据
合法性和背景调研
爬虫合法性探讨
网络爬虫领域目前还属于拓荒阶段,虽然互联网世界已经通过自己的游戏规则建立起一定的道德规范(Robots协议,全称是“网络爬虫排除标准”),但法律部分还在建立和完善中,也就是说,现在这个领域暂时还是灰色地带。
“法不禁止即为许可”,如果爬虫就像浏览器一样获取的是前端显示的数据(网页上的公开信息)而不是网站后台的私密敏感信息,就不太担心法律法规的约束,因为目前大数据产业链的发展速度远远超过了法律的完善程度。
在爬取网站的时候,需要限制自己的爬虫遵守Robots协议,同时控制网络爬虫程序的抓取数据的速度;在使用数据的时候,必须要尊重网站的知识产权(从Web 2.0时代开始,虽然Web上的数据很多都是由用户提供的,但是网站平台是投入了运营成本的,当用户在注册和发布内容时,平台通常就已经获得了对数据的所有权、使用权和分发权)。如果违反了这些规定,在打官司的时候败诉几率相当高。
Robots.txt文件
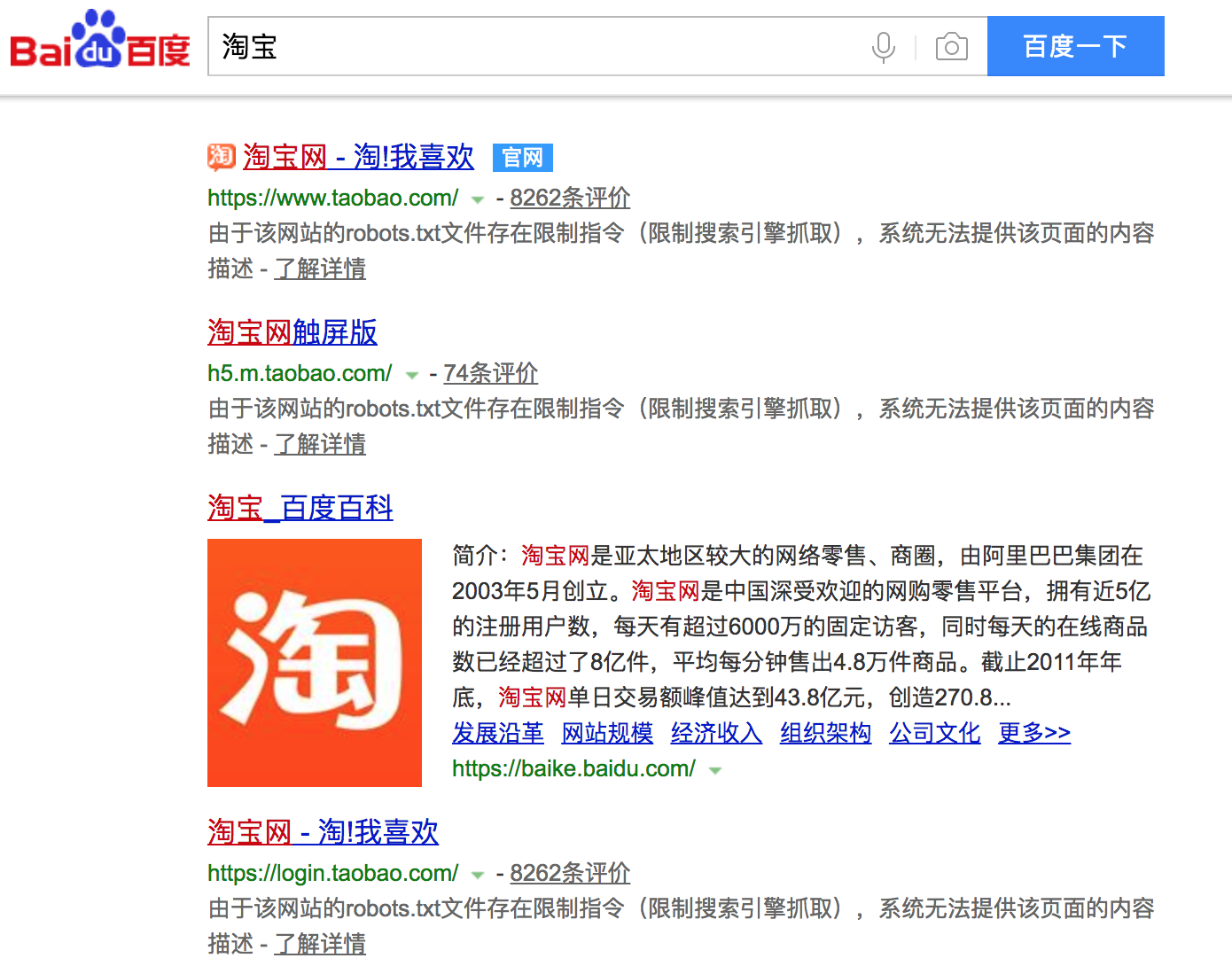
大多数网站都会定义robots.txt文件,下面以淘宝的robots.txt文件为例,看看该网站对爬虫有哪些限制。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
User-agent: Baiduspider Allow: /article Allow: /oshtml Disallow: /product/ Disallow: / User-Agent: Googlebot Allow: /article Allow: /oshtml Allow: /product Allow: /spu Allow: /dianpu Allow: /oversea Allow: /list Disallow: / User-agent: Bingbot Allow: /article Allow: /oshtml Allow: /product Allow: /spu Allow: /dianpu Allow: /oversea Allow: /list Disallow: / User-Agent: 360Spider Allow: /article Allow: /oshtml Disallow: / User-Agent: Yisouspider Allow: /article Allow: /oshtml Disallow: / User-Agent: Sogouspider Allow: /article Allow: /oshtml Allow: /product Disallow: / User-Agent: Yahoo! Slurp Allow: /product Allow: /spu Allow: /dianpu Allow: /oversea Allow: /list Disallow: / User-Agent: * Disallow: / |
注意上面robots.txt第一段的最后一行,通过设置“Disallow: /”禁止百度爬虫访问除了“Allow”规定页面外的其他所有页面。因此当你在百度搜索“淘宝”的时候,搜索结果下方会出现:“由于该网站的robots.txt文件存在限制指令(限制搜索引擎抓取),系统无法提供该页面的内容描述”。百度作为一个搜索引擎,至少在表面上遵守了淘宝网的robots.txt协议,所以用户不能从百度上搜索到淘宝内部的产品信息。
相关工具介绍
HTTP协议
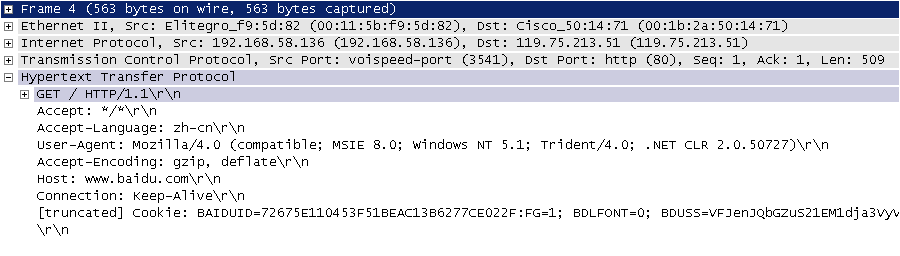
在开始讲解爬虫之前,我们稍微对HTTP(超文本传输协议)做一些回顾,因为我们在网页上看到的内容通常是浏览器执行HTML语言得到的结果,而HTTP就是传输HTML数据的协议。HTTP和其他很多应用级协议一样是构建在TCP(传输控制协议)之上的,它利用了TCP提供的可靠的传输服务实现了Web应用中的数据交换。按照维基百科上的介绍,设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法,也就是说这个协议是浏览器和Web服务器之间传输的数据的载体。关于这个协议的详细信息以及目前的发展状况,大家可以阅读阮一峰老师的《HTTP 协议入门》、《互联网协议入门》系列以及《图解HTTPS协议》进行了解,下图是我在四川省网络通信技术重点实验室工作期间用开源协议分析工具Ethereal(抓包工具WireShark的前身)截取的访问百度首页时的HTTP请求和响应的报文(协议数据),由于Ethereal截取的是经过网络适配器的数据,因此可以清晰的看到从物理链路层到应用层的协议数据。
HTTP请求(请求行+请求头+空行+[消息体]):
HTTP响应(响应行+响应头+空行+消息体):
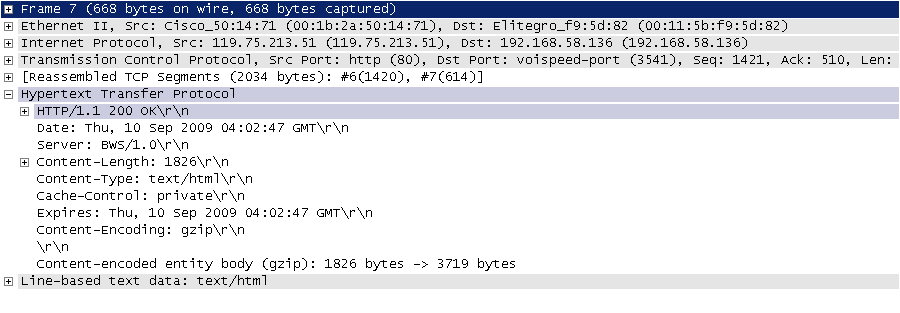
说明:但愿这两张如同泛黄照片般的截图帮助你大概的了解到HTTP是一个怎样的协议。
相关工具
- Chrome Developer Tools:谷歌浏览器内置的开发者工具。
- Postman:功能强大的网页调试与RESTful请求工具。
- HTTPie:命令行HTTP客户端。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
pip3 install httpie http --header http://www.scu.edu.cn HTTP/1.1 200 OK Accept-Ranges: bytes Cache-Control: private, max-age=600 Connection: Keep-Alive Content-Encoding: gzip Content-Language: zh-CN Content-Length: 14403 Content-Type: text/html Date: Sun, 27 May 2018 15:38:25 GMT ETag: "e6ec-56d3032d70a32-gzip" Expires: Sun, 27 May 2018 15:48:25 GMT Keep-Alive: timeout=5, max=100 Last-Modified: Sun, 27 May 2018 13:44:22 GMT Server: VWebServer Vary: User-Agent,Accept-Encoding X-Frame-Options: SAMEORIGIN |
- builtwith库:识别网站所用技术的工具。
|
1 2 3 4 5 6 7 8 9 |
pip3 install builtwith >>> import builtwith >>> builtwith.parse('http://www.bootcss.com/') {'web-servers': ['Nginx'], 'font-scripts': ['Font Awesome'], 'javascript-frameworks': ['Lo-dash', 'Underscore.js', 'Vue.js', 'Zepto', 'jQuery'], 'web-frameworks': ['Twitter Bootstrap']} >>> >>> import ssl >>> ssl._create_default_https_context = ssl._create_unverified_context >>> builtwith.parse('https://www.jianshu.com/') {'web-servers': ['Tengine'], 'web-frameworks': ['Twitter Bootstrap', 'Ruby on Rails'], 'programming-languages': ['Ruby']} |
- python-whois库:查询网站所有者的工具。
|
1 2 3 4 |
pip3 install python-whois >>> import whois >>> whois.whois('baidu.com') {'domain_name': ['BAIDU.COM', 'baidu.com'], 'registrar': 'MarkMonitor, Inc.', 'whois_server': 'whois.markmonitor.com', 'referral_url': None, 'updated_date': [datetime.datetime(2017, 7, 28, 2, 36, 28), datetime.datetime(2017, 7, 27, 19, 36, 28)], 'creation_date': [datetime.datetime(1999, 10, 11, 11, 5, 17), datetime.datetime(1999, 10, 11, 4, 5, 17)], 'expiration_date': [datetime.datetime(2026, 10, 11, 11, 5, 17), datetime.datetime(2026, 10, 11, 0, 0)], 'name_servers': ['DNS.BAIDU.COM', 'NS2.BAIDU.COM', 'NS3.BAIDU.COM', 'NS4.BAIDU.COM', 'NS7.BAIDU.COM', 'dns.baidu.com', 'ns4.baidu.com', 'ns3.baidu.com', 'ns7.baidu.com', 'ns2.baidu.com'], 'status': ['clientDeleteProhibited https://icann.org/epp#clientDeleteProhibited', 'clientTransferProhibited https://icann.org/epp#clientTransferProhibited', 'clientUpdateProhibited https://icann.org/epp#clientUpdateProhibited', 'serverDeleteProhibited https://icann.org/epp#serverDeleteProhibited', 'serverTransferProhibited https://icann.org/epp#serverTransferProhibited', 'serverUpdateProhibited https://icann.org/epp#serverUpdateProhibited', 'clientUpdateProhibited (https://www.icann.org/epp#clientUpdateProhibited)', 'clientTransferProhibited (https://www.icann.org/epp#clientTransferProhibited)', 'clientDeleteProhibited (https://www.icann.org/epp#clientDeleteProhibited)', 'serverUpdateProhibited (https://www.icann.org/epp#serverUpdateProhibited)', 'serverTransferProhibited (https://www.icann.org/epp#serverTransferProhibited)', 'serverDeleteProhibited (https://www.icann.org/epp#serverDeleteProhibited)'], 'emails': ['abusecomplaints@markmonitor.com', 'whoisrelay@markmonitor.com'], 'dnssec': 'unsigned', 'name': None, 'org': 'Beijing Baidu Netcom Science Technology Co., Ltd.', 'address': None, 'city': None, 'state': 'Beijing', 'zipcode': None, 'country': 'CN'} |
- robotparser模块:解析robots.txt的工具。
|
1 2 3 4 5 6 7 8 |
>>> from urllib import robotparser >>> parser = robotparser.RobotFileParser() >>> parser.set_url('https://www.taobao.com/robots.txt') >>> parser.read() >>> parser.can_fetch('Baiduspider', 'http://www.taobao.com/article') True >>> parser.can_fetch('Baiduspider', 'http://www.taobao.com/product') False |
一个简单的爬虫
一个基本的爬虫通常分为数据采集(网页下载)、数据处理(网页解析)和数据存储(将有用的信息持久化)三个部分的内容,当然更为高级的爬虫在数据采集和处理时会使用并发编程或分布式技术,这就需要有调度器(安排线程或进程执行对应的任务)、后台管理程序(监控爬虫的工作状态以及检查数据抓取的结果)等的参与。
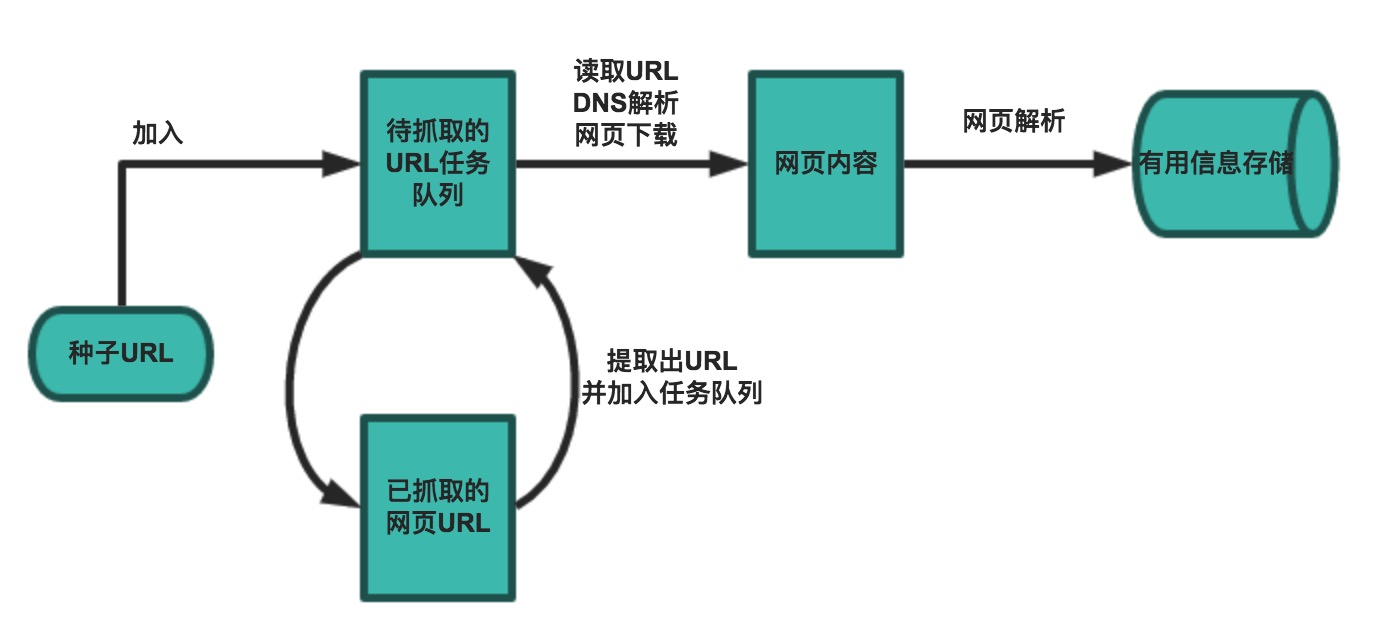
一般来说,爬虫的工作流程包括以下几个步骤:
-
- 设定抓取目标(种子页面/起始页面)并获取网页。
- 当服务器无法访问时,按照指定的重试次数尝试重新下载页面。
- 在需要的时候设置用户代理或隐藏真实IP,否则可能无法访问页面。
- 对获取的页面进行必要的解码操作然后抓取出需要的信息。
- 在获取的页面中通过某种方式(如正则表达式)抽取出页面中的链接信息。
- 对链接进行进一步的处理(获取页面并重复上面的动作)。
- 将有用的信息进行持久化以备后续的处理。
下面的例子给出了一个从“搜狐体育”上获取NBA新闻标题和链接的爬虫。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 |
import re from collections import deque from urllib.parse import urljoin import requests LI_A_PATTERN = re.compile(r'<li class="item">.*?</li>') A_TEXT_PATTERN = re.compile(r'<a\s+[^>]*?>(.*?)</a>') A_HREF_PATTERN = re.compile(r'<a\s+[^>]*?href="(.*?)"\s*[^>]*?>') def decode_page(page_bytes, charsets): """通过指定的字符集对页面进行解码""" for charset in charsets: try: return page_bytes.decode(charset) except UnicodeDecodeError: pass def get_matched_parts(content_string, pattern): """从字符串中提取所有跟正则表达式匹配的内容""" return pattern.findall(content_string, re.I) \ if content_string else [] def get_matched_part(content_string, pattern, group_no=1): """从字符串中提取跟正则表达式匹配的内容""" match = pattern.search(content_string) if match: return match.group(group_no) def get_page_html(seed_url, *, charsets=('utf-8', )): """获取页面的HTML代码""" resp = requests.get(seed_url) if resp.status_code == 200: return decode_page(resp.content, charsets) def repair_incorrect_href(current_url, href): """修正获取的href属性""" if href.startswith('//'): href = urljoin('http://', href) elif href.startswith('/'): href = urljoin(current_url, href) return href if href.startswith('http') else '' def start_crawl(seed_url, pattern, *, max_depth=-1): """开始爬取数据""" new_urls, visited_urls = deque(), set() new_urls.append((seed_url, 0)) while new_urls: current_url, depth = new_urls.popleft() if depth != max_depth: page_html = get_page_html(current_url, charsets=('utf-8', 'gbk')) contents = get_matched_parts(page_html, pattern) for content in contents: text = get_matched_part(content, A_TEXT_PATTERN) href = get_matched_part(content, A_HREF_PATTERN) if href: href = repair_incorrect_href(href) print(text, href) if href and href not in visited_urls: new_urls.append((href, depth + 1)) def main(): """主函数""" start_crawl( seed_url='http://sports.sohu.com/nba_a.shtml', pattern=LI_A_PATTERN, max_depth=2 ) if __name__ == '__main__': main() |
爬虫注意事项
通过上面的例子,我们对爬虫已经有了一个感性的认识,在编写爬虫时有以下一些注意事项:
上面的代码使用了requests三方库来获取网络资源,这是一个非常优质的三方库,关于它的用法可以参考它的官方文档。
上面的代码中使用了双端队列(deque)来保存待爬取的URL。双端队列相当于是使用链式存储结构的list,在双端队列的头尾添加和删除元素性能都比较好,刚好可以用来构造一个FIFO(先进先出)的队列结构。
处理相对路径。有的时候我们从页面中获取的链接不是一个完整的绝对链接而是一个相对链接,这种情况下需要将其与URL前缀进行拼接(urllib.parse中的urljoin()函数可以完成此项操作)。
设置代理服务。有些网站会限制访问的区域(例如美国的Netflix屏蔽了很多国家的访问),有些爬虫需要隐藏自己的身份,在这种情况下可以设置使用代理服务器,代理服务器有免费的服务器和付费的商业服务器,但后者稳定性和可用性都更好,强烈建议在商业项目中使用付费的商业代理服务器。如果使用requests三方库,可以在请求方法中添加proxies参数来指定代理服务器;如果使用标准库,可以通过修改urllib.request中的ProxyHandler来为请求设置代理服务器。
限制下载速度。如果我们的爬虫获取网页的速度过快,可能就会面临被封禁或者产生“损害动产”的风险(这个可能会导致吃官司且败诉),可以在两次获取页面数据之间添加延时从而对爬虫进行限速。
避免爬虫陷阱。有些网站会动态生成页面内容,这会导致产生无限多的页面(例如在线万年历通常会有无穷无尽的链接)。可以通过记录到达当前页面经过了多少个链接(链接深度)来解决该问题,当达到事先设定的最大深度时,爬虫就不再像队列中添加该网页中的链接了。
避开蜜罐链接。网站上的有些链接是浏览器中不可见的,这种链接通常是故意诱使爬虫去访问的蜜罐,一旦访问了这些链接,服务器就会判定请求是来自于爬虫的,这样可能会导致被服务器封禁IP地址。如何避开这些蜜罐链接我们在后面为大家进行讲解。
SSL相关问题。如果使用标准库的urlopen打开一个HTTPS链接时会验证一次SSL证书,如果不做出处理会产生错误提示“SSL: CERTIFICATE_VERIFY_FAILED”,可以通过以下两种方式加以解决:
- 使用未经验证的上下文
|
1 2 3 4 5 |
import ssl request = urllib.request.Request(url='...', headers={...}) context = ssl._create_unverified_context() web_page = urllib.request.urlopen(request, context=context) |
- 设置全局性取消证书验证
|
1 2 3 |
import ssl ssl._create_default_https_context = ssl._create_unverified_context |
本文来自这个系列长期转载Python-100-Days ,本文观点不代表蓝洛水深立场,转载请联系原作者。
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 


