
虽然已经是2024年,大家都在学python这一类工具进行爬虫采集,但是不得不说通过应用程序采集,也有其对应的优越性。
从我个人来讲,我写的python爬虫的效率,就远不如火车头,当然不是指早期的7.6这些,而是后面的9/10版本。
然而,现在很多网站都是通过json传递的数据,网络上搜索了一番,感觉虽然有人提了这方面的问题,但回答都是遮遮掩掩的,并不是很清楚。
当然,我看到很多回答说的是插件,所以,我们可以试试从插件入手。
一、火车头官方手册
下载地址:火车头手册.pdf
官方在手册中是,对插件做了简单的描述。



虽然官方在这里给了简单的说明,但是,看了感觉像没有看一样。
二、看官方的示例
官方给出了CSharp、PHP、Python三种语言的示例,说实话,Csharp的我没看明白。
好在,PHP版本的我大概看明白了,代码如下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
<?php error_reporting(E_ERROR | E_WARNING | E_PARSE); /* *外部编程接口处理标签内容示范文件 *该文件内自动系统的三个参数$LabelArray $LabelCookie,$LabelUrl *对任意采集的标签都适用请对标签内容处理后直接将该数组serialize($LabelArray)输出, *采集器内部即可接收到该标签的内容,对比以前的接口规则,新规则可以实现标签之间的数据调用和处理 *参数说明: *$LabelArray - 标签名及标签内容集合 结构如:Array('栏目id' => 2,'出处'=> '新浪微博','内容'=>'<center><b>暴笑短信') ## *$LabelCookie - 对应采集中用到的Cookie值 *$LabelUrl - 当前采集的页面的Url地址 * 特别注意:如果是处理列表页,默认页,多页时会有以下两个标签 $LabelArray['Html'] 网页的源代码,没有经过采集器处理的,直接下载后的数据.修改这里的数据,请将新值赋予$LabelArray['Html'] $LabelArray['PageType'] 值可能为 List, Content ,Pages, Save 分别代表处理列表页,默认页,多页,保存时 *以上语句建议不更改,以下为用户操作区域 该区域只限对数组值进行操作,不得有打印输出产生,不得直接增加或删除相应标签名 */ if($LabelArray['Html']) { $LabelArray['Html']='当前页面的网址为:'.$LabelUrl."\r\n页面类型为:".$LabelArray['PageType']."\r\nCookies数据为:$LabelCookie\r\n接收到的数据是:".$LabelArray['Html']; } else { $LabelArray['内容'] = $LabelArray['标题'].$LabelArray['内容']; //★★★★★★注意这句。V2009SP2版后可实现多标签之间的相互调用★★★★★★ $LabelArray['内容'] = str_replace('旧字符串','新字符串',$LabelArray['内容']); //简单替换一下 $LabelArray['标题'] = '【给标题标签加个前缀】'.$LabelArray['标题']; $LabelArray['时间'] =date('Y-m-d H:i:s',time()); //不用标签内容,直接获取time()函数得到的当前时间,用Y-m-d H:i:s格式输出,如2008-05-28 00:12:23 } //#############以上为用户操作区域############################################################################################################################# //#############以下语句必须保留,建议不更改################################################################################################################### //ob_clean(); echo serialize($LabelArray); ?> |
通过自带的插件管理,请求测试标签中,我们可以看到返回:
|
1 |
$LabelArray['Html']='当前页面的网址为:'.$LabelUrl."\r\n页面类型为:".$LabelArray['PageType']."\r\nCookies数据为:$LabelCookie\r\n接收到的数据是:".$LabelArray['Html']; |
三、定义我们的返回
起初我想的是通过定义curl访问数据后,返回给LabelArray。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
<?php $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, 'http://ztb.guizhou.gov.cn/api/trade/search?pubDate=all&pubType=all®ion=5200&industry=all&prjType=A¬iceType=A01¬iceClassify=all&pageIndex=1&args='); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_CUSTOMREQUEST, 'GET'); curl_setopt($ch, CURLOPT_HTTPHEADER, [ 'Accept: */*', 'Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'Connection: keep-alive', 'DNT: 1', 'If-Modified-Since: Thu, 25 Jan 2024 12:48:00 GMT', 'If-None-Match: "6c9befa2-0b6f-40dd-a017-6891f748fab7"', 'Referer: http://ztb.guizhou.gov.cn/trade/?prjtype=A', 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0', 'X-Requested-With: XMLHttpRequest', 'Accept-Encoding: gzip', ]); curl_setopt($ch, CURLOPT_COOKIE, '_d_id=4d10099c8291e97e71099441eba843; Hm_lvt_5f50c10002e72d2f5aa3e0563594f600=1706185117; Hm_lpvt_5f50c10002e72d2f5aa3e0563594f600=1706186846'); curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); $response = curl_exec($ch); curl_close($ch); |
但是测试后发现不对,因为火车头已经处理了这一部分。
所以,我们只需要假定$LabelArray[‘Html’]是我们所需要采集的json数据。
设置Header
那么关于数据接口所要的参数,有两个方法可以设置。
1.在其他设置中
在具体的任务中,点击其他设置,Http请求设置:
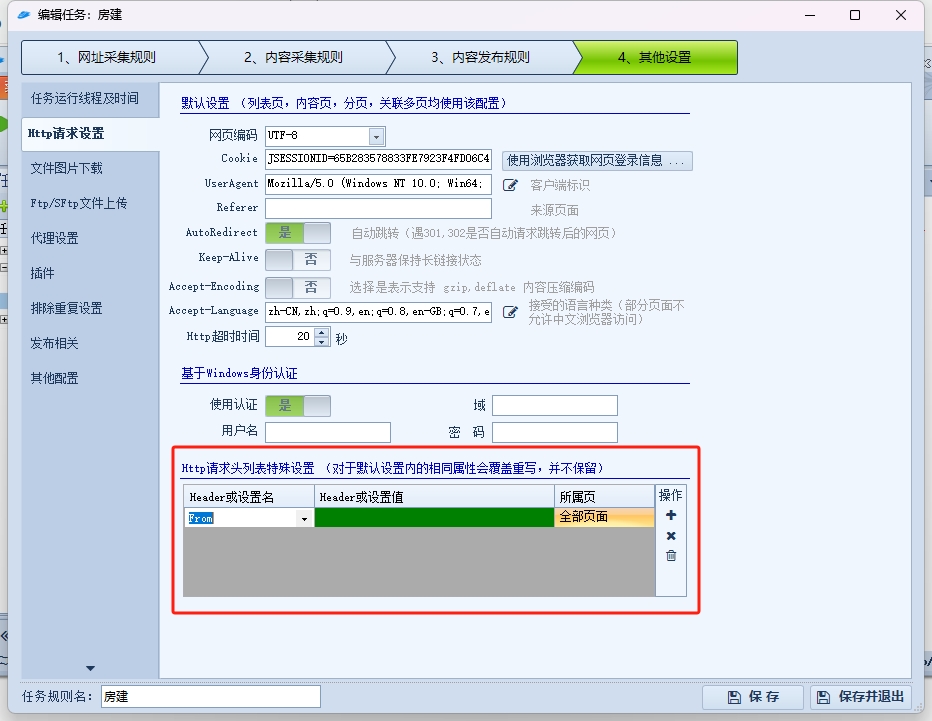
对应的设置调整为目标站点的请求参数即可。
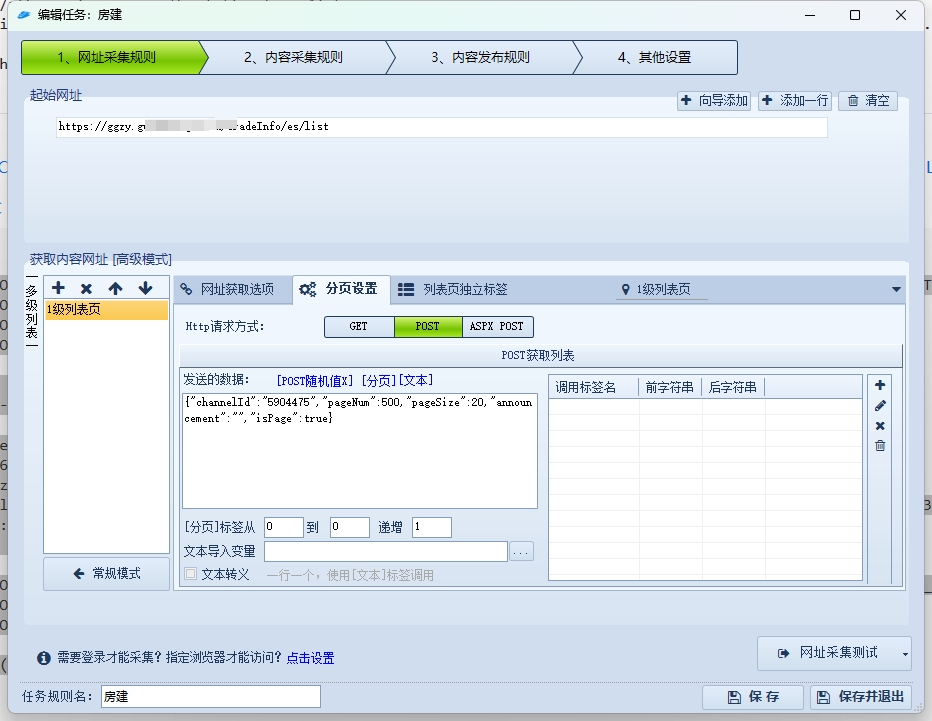
2.列表页Post
回到开头,我们遇到的困难是列表页没办法采集json数据,通过字符串截取也不行。
所以,我们也可以在列表页进行本项操作,点开网址采集的高级模式,在分页设置这里,请求方法选择POST,对应的填入自己的参数即可。
以上两个设置Header的方法,前提是在其他设置中,Http请求勾选了我们的PHP插件。
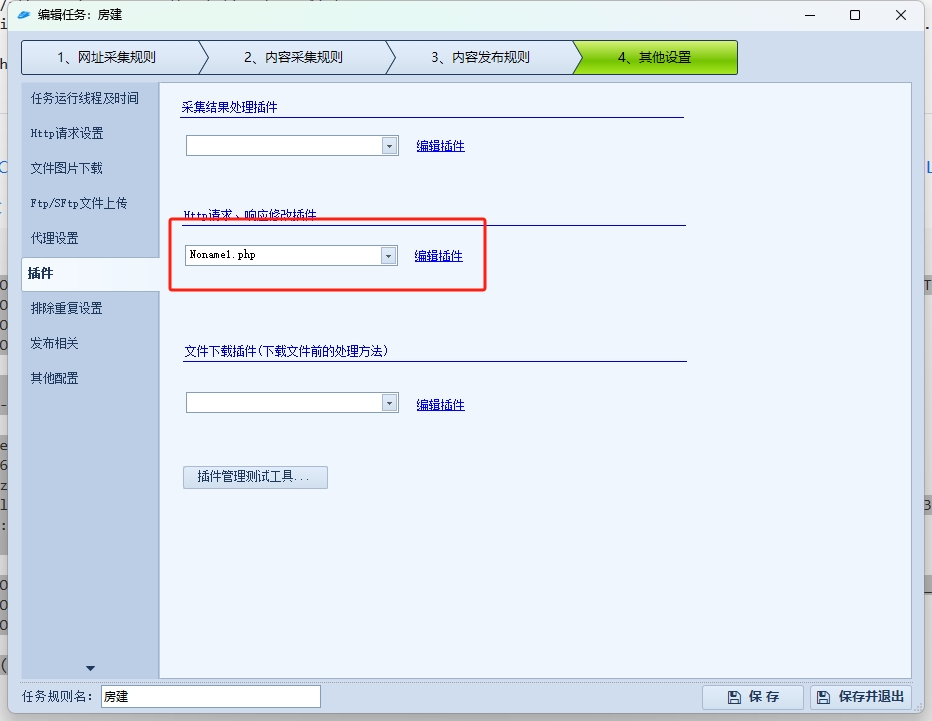
四、再次定义我们的返回
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
<?php error_reporting(E_ERROR | E_WARNING | E_PARSE); /* *外部编程接口处理标签内容示范文件 *该文件内自动系统的三个参数$LabelArray $LabelCookie,$LabelUrl *对任意采集的标签都适用请对标签内容处理后直接将该数组serialize($LabelArray)输出, *采集器内部即可接收到该标签的内容,对比以前的接口规则,新规则可以实现标签之间的数据调用和处理 *参数说明: *$LabelArray - 标签名及标签内容集合 结构如:Array('栏目id' => 2,'出处'=> '新浪微博','内容'=>'<center><b>暴笑短信') ## *$LabelCookie - 对应采集中用到的Cookie值 *$LabelUrl - 当前采集的页面的Url地址 * 特别注意:如果是处理列表页,默认页,多页时会有以下两个标签 $LabelArray['Html'] 网页的源代码,没有经过采集器处理的,直接下载后的数据.修改这里的数据,请将新值赋予$LabelArray['Html'] $LabelArray['PageType'] 值可能为 List, Content ,Pages, Save 分别代表处理列表页,默认页,多页,保存时 *以上语句建议不更改,以下为用户操作区域 该区域只限对数组值进行操作,不得有打印输出产生,不得直接增加或删除相应标签名 */ if ($LabelArray['Html']) { // json数据 $json = json_decode($LabelArray['Html'],true); $data = $json['list']; $newData = ""; foreach ($data as $key => $value) { // 替换为a标签 $newData .= "<a href='{$value['apiUrl']}'>{$value['docTitle']}</a>"; } $LabelArray['Html'] = '当前页面的网址为:' . $LabelUrl . "\r\n页面类型为:" . $LabelArray['PageType'] . "\r\nCookies数据为:$LabelCookie\r\n接收到的数据是:" . $newData; } else { $LabelArray['内容'] = $LabelArray['标题'] . $LabelArray['内容']; //★★★★★★注意这句。V2009SP2版后可实现多标签之间的相互调用★★★★★★ $LabelArray['内容'] = str_replace('旧字符串', '新字符串', $LabelArray['内容']); //简单替换一下 $LabelArray['标题'] = '【给标题标签加个前缀】' . $LabelArray['标题']; $LabelArray['时间'] = date('Y-m-d H:i:s', time()); //不用标签内容,直接获取time()函数得到的当前时间,用Y-m-d H:i:s格式输出,如2008-05-28 00:12:23 } //#############以上为用户操作区域############################################################################################################################# //#############以下语句必须保留,建议不更改################################################################################################################### //ob_clean(); echo serialize($LabelArray); |
在以上代码中,我们假定列表数据来自json数据的’list’,所以$data = $json[‘list’];
随后我们遍历这个list,假定docTitle为标题,apiUrl为链接,我们拼接为A标签,即:
|
1 2 3 4 5 |
foreach ($data as $key => $value) { // 替换为a标签 $newData .= "<a href='{$value['apiUrl']}'>{$value['docTitle']}</a>"; } |
最后,$LabelArray[‘Html’] = $newData 即可,系统原则上来说会自动从中提取出链接。
到此,我们就完成了火车头采集器爬取json列表页,希望能对您有所帮助。
原创文章,作者:蓝洛水深,如若转载,请注明出处:https://blog.lanluo.cn/12539
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 




